@EnableAsync, @Async 는 Spring에서 비동기로 작업을 처리하도록 쉽게 도와주는 어노테이션이다.
왜 ThreadPoolTaskExecutor를 등록해야 할까?
Spring의 기본 비동기 처리 Executor는 매번 새로운 쓰레드를 생성하기에, 쓰레드풀을 만들어두면 성능 개선
@EnableAsync 어노테이션을 들어가보자.
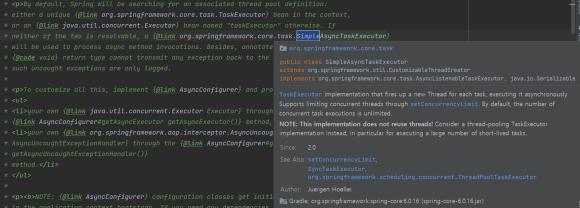
org.springframework.core.task.SimpleAsyncTaskExecutor 빈을 찾는다.
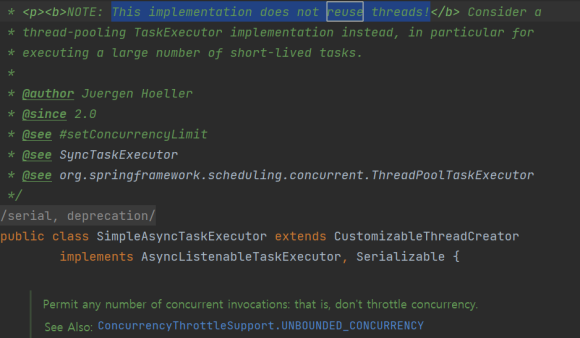
does not reuse threads
즉, 재사용하지 않고 매번 쓰레드를 생성한다.
쓰레드를 생성하는 작업은 매우 비용이 많이 드는 작업이라 쓰레드풀로 성능을 개선해보자
CPU Bound 작업보단 IO bound가 대부분인 애플리케이션 로직
Java의 Executor와 ExecutorService
Java5 출시때 java.util.concurrent 패키지에서 threading, scheduling 같은 비동기 작업을 돕는 Executor 인터페이스가 추가되었다.
- 더 이상 명시적으로 new Thread 하여 쓰레드를 생성하지 않는다.
- runnable 작업을 쉽게 실행하도록 지원
- 쓰레드 생명 주기를 개발자가 쉽게 관리
ExecutorService는 Executor 인터페이스를 확장해서 task 실행을 더욱 간편하게 했다.
Spring의 TaskExecutor
TaskExecutor를 통해서 비동기 작업에 대한 추상화를 제공한다.
SimpleAsyncTaskExecutor와 ThreadPoolTaskExecutor는 Executor를 wrapping한 TaskExecutor의 구현체이다.
ThreadPoolTaskExecutor는 ThreadPoolExecutor.java를 wrapping 한건데, 비동기 작업을 처리할 Bean으로 등록하기 위해 동작 방식을 이해해야 한다.
Executor는 쓰레드 생성을 어떻게 하는가?
bound에 따라 자동으로 풀의 크기를 조절한다.
- core pool size : idle 쓰레드 수
- max pool size : 최대 쓰레드 수
- queue capacity(waiting queue) : 가용 쓰레드가 없을때 작업이 대기하는 큐
- activeThreadCount
동작 방식
- 미리 corePoolsize만큼 쓰레드 생성
- corePoolsize를 넘어서 작업이 요청오면 큐에 적재
- 큐가 꽉 차면 쓰레드를 생성
- 쓰레드 수가 maxPoolsize까지 반복
단, maxPoolsize만큼 쓰레드를 생성했고 큐가 꽉 찼다면 요청을 거부
Java Concurrency in Practice 에서 제안하는 적정 쓰레드 풀의 크기 : 사용 가능한 코어 개수 * (1+ 대기시간/서비스 시간)
여러 쓰레드 풀이 존재할 경우 : 사용 가능한 코어 개수 * 목표 CPU 사용률 * (1+대기시간/서비스 시간)
작업 종류가 CPU bound인지 IO bound인지나 CPU 코어 개수 등에 따라 적절한 쓰레드 개수에 대해 어느 정도 정해진 규칙은 있다.
적절한 쓰레드 개수를 찾는 가장 효과적인 방법은 테스트를 통해 직접 조절해서 확인하는거다.
@EnableAsync 가 Application 클래스에 선행되어야한다. 이때 별도 설정을 하지 않으면 프록시 모드로 동작한다.
- private 메소드는 AOP 동작하지 않음
- 같은 객체 내에서 메소드 호출시 AOP 동작하지 않음
@Async는 기본적으로 SimpleAsyncTaskExecutor를 사용하는데, 이건 쓰레드 풀이 아니라 단순히 쓰레드를 만들어내는 역할을 해서 쓰레드를 관리하지 않음
Application 클래스에서 @EnableAsync를 제거하고, 아래의 configuration을 작성하자
@Configuration
@EnableAsync
public class SpringAsyncConfig {
@Bean(name = "threadPoolTaskExecutor")
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(3);
taskExecutor.setMaxPoolSize(30);
taskExecutor.setQueueCapacity(100);
taskExecutor.setThreadNamePrefix("Executor-");
return taskExecutor;
}
}
기본 쓰레드 수만큼 쓰다가 버거우면 max까지 증가하는게 아니다.
1. Integer.MAX_VALUE 사이즈의 LinkedBlockingQueue를 생성한다.
2. core 사이즈만큼 쓰레드에서 작업을 처리한다.
3. 처리못하면 Queue에서 대기한다.
이 큐가 꽉 차야 max 사이즈만큼 쓰레드를 생성한다.
Integer.MAX\_VALUE가 부담스럽다면 queueCapacity를 설정할 수 있다.
최초 3개의 스레드에서 처리하다가 처리 속도가 밀릴 경우 작업을 100개 사이즈 Queue에 넣어 놓고, 그 이상의 요청이 들어오면 최대 30개의 스레드를 생성해서 작업을 처리하게 된다.
@Async("threadPoolTaskExecutor")
public void print(String message) {
System.out.println(message);
}
참고로 Future.get()은 블로킹 함수라서 성능이 좋지 않다. ⇒ Future 쳐내
출처 및 인용.
https://docs.spring.io/spring-framework/reference/integration/scheduling.html
'backend' 카테고리의 다른 글
| DDD - Bounded Context를 정의해보자 (1) | 2024.12.24 |
|---|---|
| 성능 테스트와 개선을 위한 시도와 실패들 (0) | 2024.12.17 |
| Axon와 Kafka는 어떻게 다른가? (0) | 2024.11.23 |
| 토이프로젝트 - 트랜잭션 관리를 통한 베타락(Exclusive Lock) 구현 (0) | 2024.11.22 |
| 토이프로젝트 - Redis를 이용한 분산 락(Distributed Lock) (0) | 2024.11.22 |