고정 헤더 영역
상세 컨텐츠
본문
OOM 아닌 경우에 직접 힙 덤프 뜨는건 처음인거 같다. 겉핥기식을 넘어서 그래도 덤프 분석을 좀 진득하게 해볼 수 있었다.
Heap 메모리는 JVM 내에서 임의로 생성된 객체들이 동적으로 할당되는 공간을 말한다.
Heap의 덤프 파일은 운영중인 애플리케이션의 Heap 영역을 snapshot으로 기록한 파일을 일컫는다.
GC Logs만 놓고 분석할때는 Eden 영역이 작은지 계속 꽉 차는 일이 잦았다.
짧은 수명주기를 가지는 객체가 대부분이어서 GC시 비효율적인 메모리 사용이 생기는 것으로 보인다.
ZGC같은 경우는 과도한 CPU 사용이나 TPS 저하문제를 바로잡기 위한 튜닝이 중요하다.
Heap 영역을 넉넉하게 잡을수록 GC 주기가 길어진다. 반대로, 작으면 자주 GC를 돌려야해서 TPS가 저하하게 된다.
XX:SoftMaxHeapSize
ZGC는 Soft Max Heap을 기준으로 메모리를 유지하려고 함
즉, MaxHeap (-Xmx)을 넘지는 않지만, 가능한 이 soft max 이하에서 GC를 자주 도는 식으로 설계
-XX:SoftMaxHeapSize=1G
- Xmx2G일 때 SoftMaxHeapSize를 1G로 주면 실제 사용 메모리는 1G 근처를 유지하려고 함
- ZGC 튜닝
- XX:ZCollectionInterval - ZGC가 얼마나 자주 GC를 수행할지 설정
- 너무 자주 GC를 수행하면 TPS가 떨어짐
- XX:ZUncommitDelay - 메모리 반환 주기를 조정
- XX:ZCollectionInterval - ZGC가 얼마나 자주 GC를 수행할지 설정
- 메모리 리소스 최적화
- JVM 메모리의 Xms와 Xmx를 적절히 설정
- XX:+UseLargePages - 큰 페이지 메모리를 활용
힙 덤프를 분석해서 어떤 객체들이 많이 남았는지, 누가 루트를 잡고 있는지 확인해보고 코드를 개선해보겠다.
ps aux | grep java : PID 확인 (근데 1번일거임)
- jmap -dump:format=b,file=heap.hprof <PID>
- jcmd 1 GC.heap_dump /heapdump/heapdump-$(date +%Y%m%d%H%M%S).hprof
Java에서 아무 경로도 안 주고 jcmd, jmap, -XX:+HeapDumpOnOutOfMemoryError 등으로 힙덤프를 뜨면 현재 작업 디렉토리 (working directory) 에 생성된다.
컨테이너 안의 루트 디렉토리에서 heapdump.hprof 를 찾을 수 있다. 그리고 난 원래 Dockerfile 만들때 FROM openjdk:21-slim 했는데, slim은 JDK라기보단 JRE에 가까운 런타임 환경만 포함하고 있어서 가볍다.
jcmd이나 jmap이 없다는 말이여!!!!!!
그래서 힙덤프 딸떄는 FROM openjdk:21으로 해야한다.
Eclipse MAT 도구로 힙 덤프를 분석해보자
환경 : AWS EC2 or OnPremise, JDK 21(ZGC), Spring Boot 3.4.0, MySQL In Docker Container
G1 GC에 비해서 낮은 처리량을 해결하고자 튜닝을 진행하기에 앞서, 애플리케이션에서 주로 발생하는 메모리 적재 상태를 분석하고자 힙 덤프를 분석하는거다.
초기 애플리케이션 초기화 시점에서부터 성능 테스트 전후로 3개씩 덤프를 떠서 비교했다. 자동 분석 결과를 추천할때, Leak suspects report를 열어서 코드상 메모리 누수되는 부분을 함께 해결하겠다.
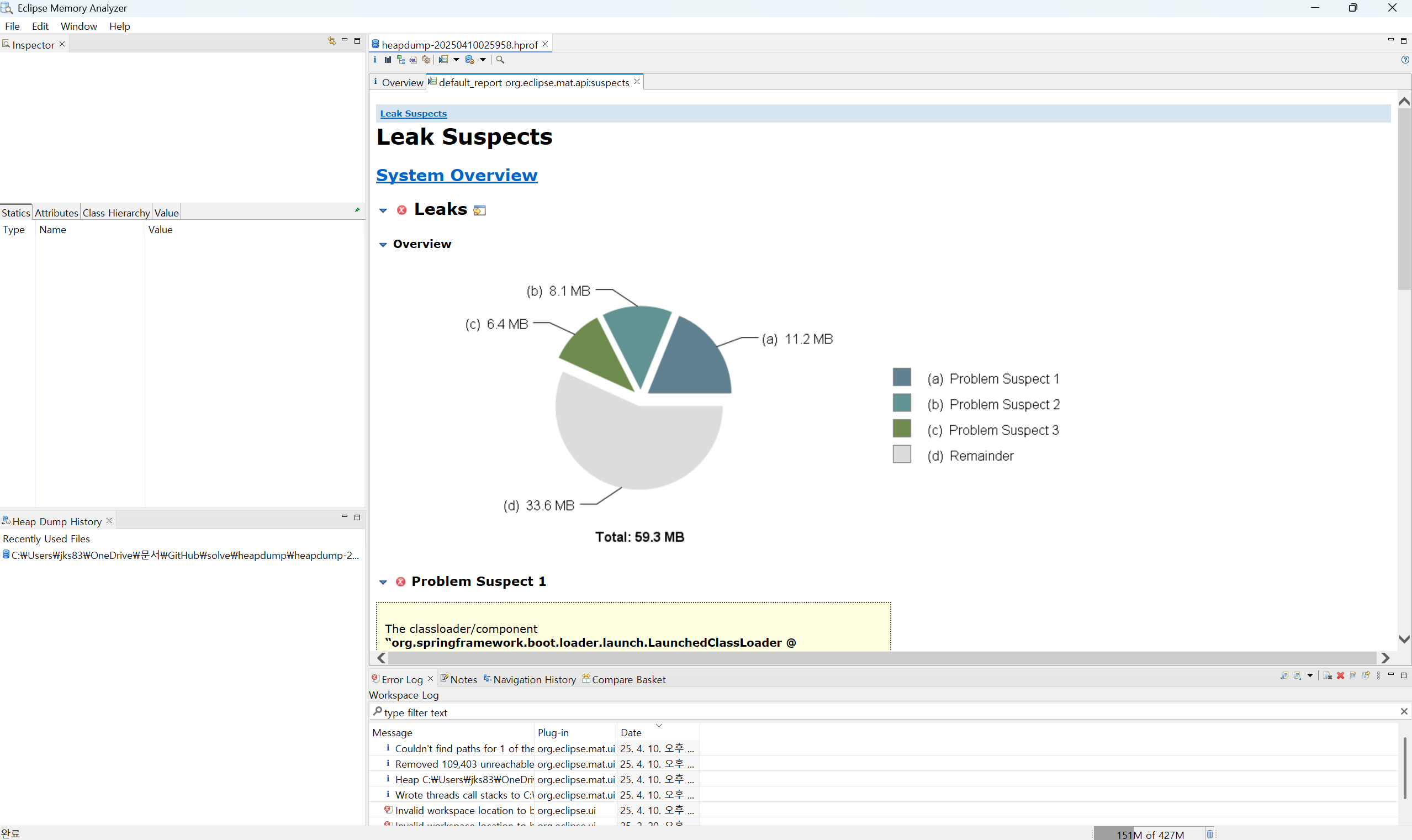
얘네가 분석하면서 메모리 누수로 의심되는 구간도 알려준다.

이처럼 메모리 누수를 분석해주는걸 보편적으로 가장 많이 사용했을거다.
하지만 우리의 목적은 Heap Pressure를 줄이기 위해서 분석하는거라 Dominator Tree나 Top Consumers를 봐야 한다.
애플리케이션에서 대용량 객체를 보유하는 클래스가 많은가? 혹은 긴 LifeCycle의 객체가 처리량 감소의 원인인지 판별해야한다.
Dominator Tree 분석

Retinaed Heap이 얼마나 많은 객체를 “붙잡고 있는지(retained)” 확인할 수 있다.
부하 테스트로 트래픽을 주입했을때 우리 애플리케이션은 불필요하게 생성된 ArrayList, ConcurrentHashMap가 많았다.
그중에서 java.util.ArrayList @ 0x10000fb8fb70는 가장 많은 Retained Heap을 차지하고 있고, 전체 힙의 15.85%를 Hold하고 있었다.
이 객체는 확실히 GC가 회수하지 못하고 있고, 애플리케이션에서 지나치게 많은 객체를 참조하고 있다.
머지
GC Root를 타고 들어가보니 com.mysql.cj.jdbc.AbandonedConnectionCleanupThread까지 닿았다.
MySQL JDBC Driver가 생성한 내부 리소스를 제대로 해제하지 못해서 메모리를 많이 차지하던 거다.
JVM 튜닝 결론 - young generation 영역을 좀 더 확보하자
Oracle 문서 내용중 - https://docs.oracle.com/javase/8/docs/technotes/guides/troubleshoot/memleaks002.html
You can use the parameter SurvivorRatio can be used to tune the size of the survivor spaces, but this is often not important for performance.
For example, -XX:SurvivorRatio=6 sets the ratio between eden and a survivor space to 1:6.
In other words, each survivor space will be one-sixth the size of eden, and thus one-eighth the size of the young generation (not one-seventh, because there are two survivor spaces).
- 결국 STW가 발생하는 것은 Young Gen → Old Gen으로 옮기는 과정인 Major GC 에서 발생한다
- 그러므로 Young Gen 영역에서 발생하는 Minor GC를 적극적으로 활용하면 STW를 줄일 수 있다
- 그렇기때문에 Young Gen은 Old Gen의 2배로 설정하는게 효율적이다 (-XX:NewRadio=2)
- 그리고 Survivor 영역은 Young Gen에 8/1 정도로 설정하는걸 권장한다고 한다 (-XX:SurvivorRatio=8)
'spring' 카테고리의 다른 글
| 토스가 겪은 Reactor Netty의 Memory Leak 이슈를 알아보자 (4) | 2025.08.18 |
|---|---|
| AOP를 이용한 @Transactional의 동작 원리 (feat. 트랜잭션의 범위, 전파) (1) | 2025.07.12 |
| What Color is Your Function? (feat. 함수의 색 전염성) (0) | 2025.03.12 |
| Java도 한다 경량 쓰레드 (Virtual Thread) (0) | 2025.02.26 |
| JVM의 Garbage Collector 분석 (feat. ZGC와 G1간의 차이점 비교) (0) | 2025.02.26 |




